Unsupervised Self-Adaptive Auditory Attention Decoding
Abstract
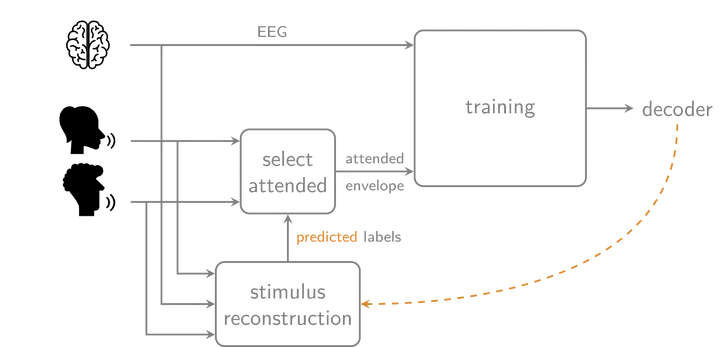
When multiple speakers talk simultaneously, a hearing device cannot identify which of these speakers the listener intends to attend to. Auditory attention decoding (AAD) algorithms can provide this information by, for example, reconstructing the attended speech envelope from electroencephalography (EEG) signals. However, these stimulus reconstruction decoders are traditionally trained in a supervised manner, requiring a dedicated training stage during which the attended speaker is known. Pre-trained subject-independent decoders alleviate the need of having such a per-user training stage but perform substantially worse than supervised subject-specific decoders that are tailored to the user. This motivates the development of a new unsupervised self-adapting training/updating procedure for a subject-specific decoder, which iteratively improves itself on unlabeled EEG data using its own predicted labels. This iterative updating procedure enables a self-leveraging effect, of which we provide a mathematical analysis that reveals the underlying mechanics. The proposed unsupervised algorithm, starting from a random decoder, results in a decoder that outperforms a supervised subject-independent decoder. Starting from a subject-independent decoder, the unsupervised algorithm even closely approximates the performance of a supervised subject-specific decoder. The developed unsupervised AAD algorithm thus combines the two advantages of a supervised subject-specific and subject-independent decoder: it approximates the performance of the former while retaining the ‘plug-and-play’ character of the latter. As the proposed algorithm can be used to automatically adapt to new users, as well as over time when new EEG data is being recorded, it contributes to more practical neuro-steered hearing devices.
This article was a featured article in IEEE Journal on Biomedical and Health Informatics in October 2021. A video abstract is available on Youtube.
Simon Geirnaert
Postdoctoral researcher
My research interests include signal processing algorithm design for multi-channel biomedical sensor arrays (e.g., electroencephalography) with applications in attention decoding for brain-computer interfaces.